Recurrent Neural Network (Professor 李宏毅 ML #26 45-90 mins)
Ben 03/13/2018
有了seq 2 seq的技術之後,就可做到beyond sequence
e.g. 讓machine產生syntactic parsing tree
要如何讓machine得到一個樹狀結構呢?
過去要用structure learning的技術,才能夠解這個問題。現在只要把樹狀圖描述成一個sequence,用seq2seq model的output就是一個syntactic parsing tree就可training 起來,下圖就把一句話描述成seq的例子。

把一個document表示成一個vector的話,之前會用bag-of-word的方法,但會忽略”word order”
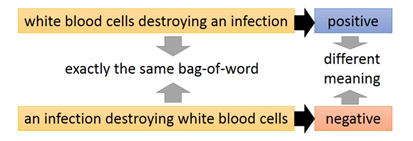
在Word sequence的情況下,來解決字彙量一樣,但組起來語句不同的問題 =>
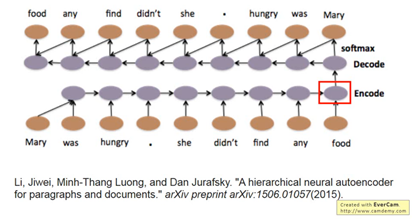
透過RNN把一組Word sequence變成embedded vector,當成decoder的輸入,讓decoder找回一個一模一樣的句子,換句話說,就是embedded vector具有重要的資訊。
seq2seq auto-encoder 不需要label data,只需要丟入大量的data即可。
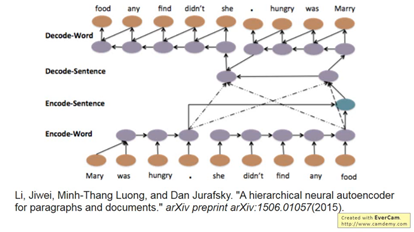
可具有hierarchy,也就是說每個句子都先得到一個vector。每個句子的vector相加之後= document high level vector丟入decoder,再反向解回word,這就是一個自成的LSTM,順序就是word seq=> sentence seq=> document level => sentence seq => word seq
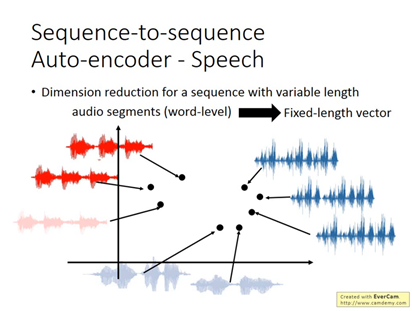
用在 speech中,可以把audio segments(word-level) 轉成一個fixed-length vector,可以用再甚麼地方呢?e.g.語音搜尋,不需要聲音辨識,只需要做聲音相似度的辨識即可。audio segment to vector
使用者說了一段語音之後,也將audio轉成vector,比對相似性,找出是否相同。
Audio segment => acoustic features => RNN encoder => RNN Decoder (encoder & decoder是一起train的)
用seq2seq autoencoder來訓練chat-bot:收集很多的對話(電視影集4萬多句+美國大選辯論)
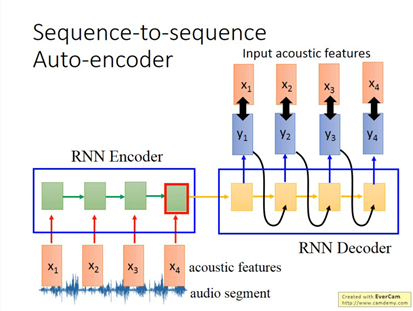
LSTM encoder => LSTM decoder,腦中會記得很多事情,也會自動忽略無關緊業的事情,當問一件事情的時候,就會去提取相關的資訊。
除了RNN以外,attention-based model具有memory,常被用在reading comprehension,讓機器去讀文件,每句話都會變成vector,Query=> 中央處理器(DNN/RNN)去控制reading head controller,讀取的過程可以是iterative,也就是會到很多地方去讀information,如果讀到相關的information之後,就把header放在上面,再放回去DNN/RNN=> get answer
Input => DNN/RNN => ouput
多了reading head controller 及writing head controller,稱為Neural Turing Machine
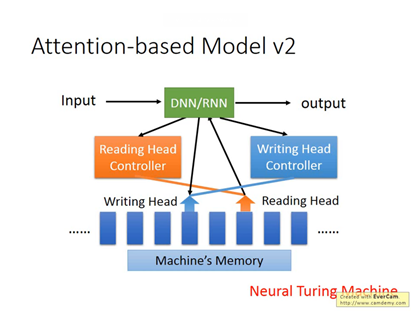
讓機器做reading comprehesion:what color is Greg? 藍色代表reading head放的位置,Hop代表放的時間點,透過三次的讀寫,透過Neural netwrok,機器自己學到的。
那怎麼樣才能做到visual question answer?例如看一張香蕉
先讓CNN去讀圖,丟入了Query後,reading heading會去讀取很多次的資訊。
讓機器做speech question answering
問題轉成語義分析
聲音辨識轉成語義分析 => 機器了解聲音和問題的語義後,畫重點,之後就去比對,產生答案之後,還會在比對相似度,再去修正畫的重點。
example是在處理讀一句話回答答案
給機器visual / 語音輸入(TOFEL),來回答答案
實驗結果 隨意猜的結果是25%
找最短的答案 或是 比對一選項和另外三個選項語義相似度,這兩種方法可以到達35%
Memory Network 可以達到39.2%
proposed approach:可以到達48.8%

RNN & Structure Learning的關係 (應該就會是未來的一個研究方向)
| RNN, LSTM | HMM, CRF, Structured Perceptron/SVM |
|---|---|
| Unidirectional RNN不考慮整個seq | 因為用Viterbi,所以可考慮整個seq |
| Cost和error往往沒有關係 | 可以explicitly去考慮label間關係,Cost function是error的上界 |
| 可以是deep | |
| Deep Leaning可以佔到比較大的優勢 |
RNN+LSTM考慮的cost是考慮交叉 火商
底部Input feature 先通過RNN/LSTM,oupput再餵到HMM, CRF, Structured Perceptron/SVM

語音辨認常見的組合 : CNN/LSTM/DNN +HMM
要去計算x和y的evaluation function,x是生醫訊號,y是語音辨識的結果
RNN是一個一個frame去看,DNN就是取代immession的部份,要的是P(xl|yl)
假若不同的錯誤對於語音辨識的影響很大,但RNN認不出這件事情,因此需要加上HMM

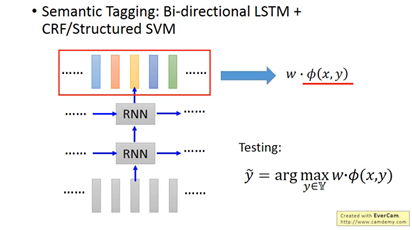
語意tagging: Bi-directional LSTM+ CRF/Structured SVM
先用Bi-directional LSTM抽出features,再拿這些features定義CRF/Structured SVM需要的features
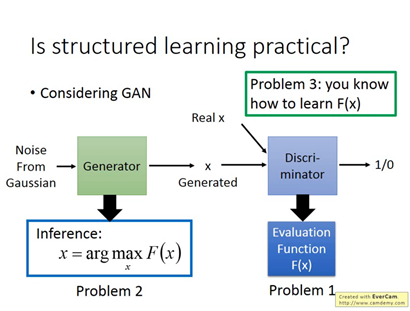
Structure learning要解三個問題
Inference
解inference的問題,要窮舉所有的可能(因此往往最困難)
How to learn how to learn F(x)
把GAN中的discriminator看成 evaluation function可以解Problem 1
把generator當成可以窮舉所有的可能,就是解inference窮舉的問題,可以解problem 2
Conditional GAN
Discriminator會去Check real (x,y) pair
Input x => image y => discriminator 就會去檢查畫和圖是不是一樣?
GAN 和energy-based model 結合起來了
learning需要有cost function (也稱做loss function)。cost function就是計算entropy。是每個時間點的cross entropy。有了loss function後,便將loss function對w (weight,RNN的權重參數)微分。BPTT的演算法來計算這些微分運算。RNN不容易訓練,loss很容易沒有收斂。過去以為是有程式bug。後來發現其實是RNN的error surface很不平滑。就像是懸涯峭壁,懸崖上的的gradient很大,若是踩在懸崖上,調整參數(w)之後就飛出去了。
Recurrent neural network training data就是訓練RNN的資料。(這邊再聽一次便再補進文章)
[0]
H. Y. Lee, ML lecture #26, RNN part II, at